Hi All.
How can I query value “No” on both redhat and google site on a file with below lines. Thanks
“HOSTNAME Port Test”
“ftp.redhat.com”,“21”,“No”
“google.com”,“80”,“No”
Hi All.
How can I query value “No” on both redhat and google site on a file with below lines. Thanks
“HOSTNAME Port Test”
“ftp.redhat.com”,“21”,“No”
“google.com”,“80”,“No”
following texts of firsts "," or following texts of firsts "," of lines of fileThanks for the reply Sir. Why I am getting below output when running fixlet debugger on a Win2008 R2 server? Thanks
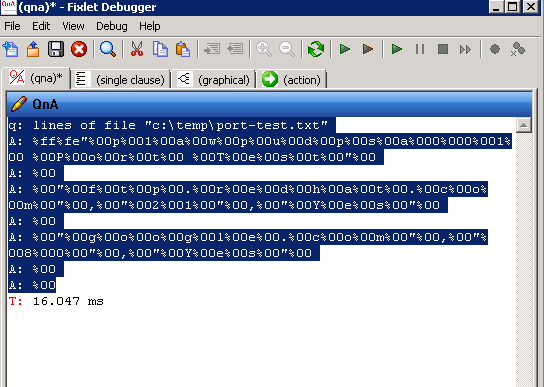
Looks like the file is UNICODE text and you’re using a BigFix version earlier than 9.5. In 9.5 IBM introduced native UNICODE file handling. Pre-9.5 the embedded double-byte characters are all represented in the output and not handled as a single character.
The first two bytes, “fffe” indicate the file encoding type. I haven’t tried this on a UNICODE file yet but I expect this should give what you expect by stripping out the unprintable characters:
q: (concatenation of characters whose ( it as hexadecimal as integer < 127 and it as hexadecimal as integer > 31) of it)of lines of file "c:\temp\port-test.txt"
That should strip off the %00 in the double-byte characters, as well as the %ff%fe header, and anything else outside the “normal ASCII” range of printable characters.
And props to @jgstew, whose Challenge #3 at Challenge #3: What does this relevance do? is my constant reference on this 
How to replace a string?
I use concatenation
concatenation “bye” of substrings separated by “hello” of lines of file “test.txt”
hellotesthello
but the output is in one line: byetestbye
instead of
bye
test
bye
Hi! I’m not making any progress on my own… how can I specify a range for “lines of file” please (to get the first or last 10 lines for example)?
Try
lines whose (line number of it <= 10) of files "{path_to_your_file}"
Yes! Beautiful, thank you!