Need to get names of latest 5 txt files modified within a folder.
Seems like it should be simple, but it turns out to be a bit tricky.
Start with the collection of files in the folder and filter for filename ending .txt
q: (name of it, modification time of it) of files whose (name of it as lowercase ends with ".txt") of folder "c:\test"
A: another file 3.txt, ( Wed, 27 Jan 2021 12:59:09 -0500 )
A: DLV cscript command.txt, ( Wed, 01 Apr 2020 11:16:41 -0500 )
A: dlv.txt, ( Wed, 01 Apr 2020 11:15:47 -0500 )
A: Fake.txt, ( Tue, 02 Jun 2020 14:24:49 -0500 )
A: new file 1.txt, ( Wed, 27 Jan 2021 12:59:02 -0500 )
A: NewFile.txt, ( Wed, 27 Jan 2021 12:58:49 -0500 )
A: NewFile2.txt, ( Wed, 27 Jan 2021 12:58:56 -0500 )
A: one more file 5.txt, ( Wed, 27 Jan 2021 12:59:17 -0500 )
I also included the modification time in there as a tuple (comma).
Now, getting the first x or last x of a thing will require us to make some sort of ordered list, but we don’t have a "sort by " object in relevance… so we will have to get creative. Let’s calculate the age in seconds, by subtracting the modification times from Now, and add a “Unique values” to sort it by how many seconds old.
q: unique values of (it as string) of ( (now - modification time of it)/second, name of it) of files whose (name of it as lowercase ends with ".txt") of folder "c:\test"
A: 1272, one more file 5.txt
A: 1280, another file 3.txt
A: 1287, new file 1.txt
A: 1293, NewFile2.txt
A: 1300, NewFile.txt
A: 20645740, Fake.txt
A: 26013828, DLV cscript command.txt
A: 26013882, dlv.txt
Then we have to stack them together into a string, with a separator… and then count the separators to get our “top 5”. you can concatenate with ", " and then inspect with Tuple String Items to solve this portion
q: (tuple string items (0;1;2;3;4) of it) of concatenation ", " of (it as string) of unique values of ((now - modification time of it)/second) of files whose (name of it as lowercase ends with ".txt") of folder "c:\test"
A: 1072
A: 1080
A: 1087
A: 1093
A: 1100
Then you need to put sets around both, and then expand both sets (almost there…)
q: (elements of item 0 of it, elements of item 1 of it) of (set of (tuple string items (0;1;2;3;4) of it) of concatenation ", " of (it as string) of unique values of ((now - modification time of it)/second) of files whose (name of it as lowercase ends with ".txt") of folder "c:\test", set of unique values of (it as string) of ( (now - modification time of it)/second, name of it) of files whose (name of it as lowercase ends with ".txt") of folder "c:\test")
A: 1431, ( 1431, one more file 5.txt )
A: 1431, ( 1439, another file 3.txt )
A: 1431, ( 1446, new file 1.txt )
A: 1431, ( 1452, NewFile2.txt )
A: 1431, ( 1459, NewFile.txt )
A: 1431, ( 20645899, Fake.txt )
A: 1431, ( 26013987, DLV cscript command.txt )
A: 1431, ( 26014041, dlv.txt )
A: 1439, ( 1431, one more file 5.txt )
and add a filter to find the matches
q: (elements of item 0 of it, elements of item 1 of it) whose (item 1 of it starts with (item 0 of it & ", ")) of (set of (tuple string items (0;1;2;3;4) of it) of concatenation ", " of (it as string) of unique values of ((now - modification time of it)/second) of files whose (name of it as lowercase ends with ".txt") of folder "c:\test", set of unique values of (it as string) of ( (now - modification time of it)/second, name of it) of files whose (name of it as lowercase ends with ".txt") of folder "c:\test")
A: 1533, ( 1533, one more file 5.txt )
A: 1541, ( 1541, another file 3.txt )
A: 1548, ( 1548, new file 1.txt )
A: 1554, ( 1554, NewFile2.txt )
A: 1561, ( 1561, NewFile.txt )
and finally to de-tuple to just the file names.
q: tuple string items 1 of items 1 of (elements of item 0 of it, elements of item 1 of it) whose (item 1 of it starts with (item 0 of it & ", ")) of (set of (tuple string items (0;1;2;3;4) of it) of concatenation ", " of (it as string) of unique values of ((now - modification time of it)/second) of files whose (name of it as lowercase ends with ".txt") of folder "c:\test", set of unique values of (it as string) of ( (now - modification time of it)/second, name of it) of files whose (name of it as lowercase ends with ".txt") of folder "c:\test")
A: one more file 5.txt
A: another file 3.txt
A: new file 1.txt
A: NewFile2.txt
A: NewFile.txt
I wonder if any others can create a neater/tighter/more clever solve?
Smells like a Relevance Challenge!! @jgstew
(as a side note, you can see my files getting older as I run my queries… looks like it took me about 1561 seconds to solve this)
8 Likes
Impressive as always! 
1 Like
Thank You for the solution provided. 
1 Like
unique values will sort the modification times as is:
tuple string items ( integers in(number of tuple string items of it - 5, number of tuple string items of it - 1) ) of concatenations ", " of following texts of firsts ", " of (it as string) of unique values of modification times of files of folders "/tmp"
This gives you the 5 newest unique modification times of all files in the folder.
Then, sub optimally, I enumerate all the files to get the modification times, then again to compare:
pathnames of files whose(modification time of it as string is contained by set of (it as string) of (it as time) of tuple string items ( integers in(number of tuple string items of it - 5, number of tuple string items of it - 1) ) of concatenations ", " of following texts of firsts ", " of (it as string) of unique values of modification times of files of folders "/tmp" ) of folders "/tmp"
This will give the 5 newest files in the folder. To get the 5 newest .txt files, you would add a filter to the whose statement(s) to only have it return txt files.
It is very likely that my relevance could also be more efficient to only enumerate the files once instead of twice, but that would take me more time to try to figure out how to optimize it.
3 Likes
Nice refinement.
I expected that unique values would not be smart enough to date sort, so I skipped that method.
Turns out it is smart enough:
q: unique values of modification times of files of folder "c:\test"
A: Fri, 06 Dec 2019 11:16:00 -0500
A: Tue, 14 Jan 2020 13:10:59 -0500
A: Wed, 01 Apr 2020 11:15:47 -0500
A: Wed, 01 Apr 2020 11:16:10 -0500
A: Wed, 01 Apr 2020 11:16:41 -0500
A: Wed, 01 Apr 2020 11:19:48 -0500
A: Wed, 01 Apr 2020 11:26:43 -0500
A: Wed, 01 Apr 2020 11:43:49 -0500
A: Wed, 01 Apr 2020 13:44:07 -0500
A: Wed, 01 Apr 2020 13:44:29 -0500
A: Tue, 02 Jun 2020 14:24:49 -0500
A: Wed, 27 Jan 2021 12:58:49 -0500
A: Wed, 27 Jan 2021 12:58:56 -0500
A: Wed, 27 Jan 2021 12:59:02 -0500
A: Wed, 27 Jan 2021 12:59:09 -0500
A: Wed, 27 Jan 2021 12:59:17 -0500
A: Fri, 29 Jan 2021 17:54:44 -0500
A: Fri, 29 Jan 2021 17:54:53 -0500
A: Fri, 29 Jan 2021 17:55:04 -0500
A: Fri, 29 Jan 2021 17:55:13 -0500
A: Fri, 29 Jan 2021 17:55:23 -0500
2 Likes
Nice thought. Inspired me to put this solve together.
The hard part about these types of problems is that as soon as you use an it clause, you iterate the object and can no longer aggregate.
q: maximum of modification times of files of folders ("/tmp";"c:\test")
A: Fri, 29 Jan 2021 17:55:23 -0500
T: 12.515 ms
I: singular time
q: (maximum of it) of modification times of files of folders ("/tmp";"c:\test")
A: Fri, 29 Jan 2021 17:55:23 -0500
A: Fri, 29 Jan 2021 17:55:13 -0500
A: Wed, 27 Jan 2021 12:58:49 -0500
A: Fri, 29 Jan 2021 17:54:44 -0500 ...
So the typical solve is to use the file object twice, adding expense, but allowing you to find the max of the group and then whose to find the matching instance.
q: (maximum of modification times of files of folders ("/tmp";"c:\test"), modification times of files of folders ("/tmp";"c:\test"))
A: ( Fri, 29 Jan 2021 17:55:23 -0500 ), ( Fri, 29 Jan 2021 17:55:23 -0500 )
A: ( Fri, 29 Jan 2021 17:55:23 -0500 ), ( Fri, 29 Jan 2021 17:55:13 -0500 )
A: ( Fri, 29 Jan 2021 17:55:23 -0500 ), ( Wed, 27 Jan 2021 12:58:49 -0500 )
A: ( Fri, 29 Jan 2021 17:55:23 -0500 ), ( Fri, 29 Jan 2021 17:54:44 -0500 )
A: ( Fri, 29 Jan 2021 17:55:23 -0500 ), ( Wed, 27 Jan 2021 12:59:09 -0500 )
A: ( Fri, 29 Jan 2021 17:55:23 -0500 ), ( Fri, 29 Jan 2021 17:54:53 -0500 ) …
Your use of tuple string items inspired using a string set to pull all the “stuff” about the files into a set, thus allowing me to work on the set both as individual elements, as well as in aggregate, without needing to endure the expense of creating the file objects a second time. (This only works for things that can be coerced into strings and then back to their original object types after the set maneuver - I wish we had a Set object for Filesystem Objects available in relevance!)
q: (maximum of (it as time) of elements of it, (it as time) of elements of it) of set of (it as string) of modification times of files of folders ("/tmp";"c:\test")
A: ( Fri, 29 Jan 2021 17:55:23 -0500 ), ( Fri, 06 Dec 2019 11:16:00 -0500 )
A: ( Fri, 29 Jan 2021 17:55:23 -0500 ), ( Fri, 29 Jan 2021 17:54:44 -0500 )
A: ( Fri, 29 Jan 2021 17:55:23 -0500 ), ( Fri, 29 Jan 2021 17:54:53 -0500 )
A: ( Fri, 29 Jan 2021 17:55:23 -0500 ), ( Fri, 29 Jan 2021 17:55:04 -0500 )
A: ( Fri, 29 Jan 2021 17:55:23 -0500 ), ( Fri, 29 Jan 2021 17:55:13 -0500 )
A: ( Fri, 29 Jan 2021 17:55:23 -0500 ), ( Fri, 29 Jan 2021 17:55:23 -0500 ) <<<
To apply this, along with your very neat method of counting tuple string items and subtracting and using Integers in, to our use case. I think this is a nicely efficient refinement.
q: items 0 of items 1 of ((tuple string items ( integers in(number of tuple string items of it - 5, number of tuple string items of it - 1) ) of concatenations ", " of following texts of firsts ", " of (it as string) of unique values of tuple string items 1 of elements of it), (tuple string items 0 of it, following texts of firsts ", " of tuple string items 1 of it) of elements of it) whose (item 0 of it = item 1 of item 1 of it) of set of (it as string) of (name of it, modification time of it) of files of folders ("/tmp";"c:\test")
A: Abc_20210121225468.txt
A: test4_20210126224733.txt
A: test3_20210125205107.txt
A: Abc_20210124184449.txt
A: one more file 5.txt
T: 6.299 ms
2 Likes
Very cool! My relevance seemed to be slightly slower than yours, but with this optimization, it seems consistently much faster than either of the other options. I figured there had to be some way to read the files a single time with sets, but I couldn’t figure it out.
What is really nice about having it optimized this way is that it gets slower linearly as more files are in the folder, but both of the other methods get slower by a factor of 2 as more files are in the folder that must be examined, which can lead to a situation were you write relevance that seems fast enough in testing, but then in production with many files it gets problematically slow.
I also tried and failed to only get the value for number of tuple string items of it one time in here: integers in(number of tuple string items of it - 5, number of tuple string items of it - 1) but that seems like a more fundamental issue in the way the relevance evaluates it.
1 Like
Noticed we flipped the sort somewhere along the way. corrected that and added in your suggestion above as well as a trap for “there are less than 5 files”.
(tuple string items ((integers in (it-1,maximum of (it-5;0))) of (number of tuple string items of it)) of it)
This is getting pretty crisp!
Overall Folder contents
(yea, I have a lot of junk in my test box…)
q: (modification time of it, name of it) of files of folders ("/tmp";"c:\test")
A: ( Fri, 29 Jan 2021 17:55:23 -0500 ), Abc_20210115612456.txt
A: ( Fri, 29 Jan 2021 17:55:13 -0500 ), Abc_20210120342156.txt
A: ( Wed, 27 Jan 2021 12:58:49 -0500 ), Abc_20210121225468.txt
A: ( Fri, 29 Jan 2021 17:54:44 -0500 ), Abc_20210123165009.txt
A: ( Wed, 27 Jan 2021 12:59:09 -0500 ), Abc_20210124184449.txt
A: ( Fri, 29 Jan 2021 17:54:53 -0500 ), Abc_20210125205107.txt
A: ( Fri, 29 Jan 2021 17:55:04 -0500 ), Abc_20210126224733.txt
A: ( Wed, 01 Apr 2020 11:16:41 -0500 ), DLV cscript command.txt
A: ( Wed, 01 Apr 2020 11:16:10 -0500 ), DLV parse for Win 7.qna
A: ( Wed, 01 Apr 2020 11:15:47 -0500 ), dlv.txt
A: ( Tue, 02 Jun 2020 14:24:49 -0500 ), Fake.txt
A: ( Fri, 06 Dec 2019 11:16:00 -0500 ), Install Multiple Activation Key.url
A: ( Wed, 01 Apr 2020 11:43:49 -0500 ), LicenseStatus Values.url
A: ( Wed, 27 Jan 2021 12:59:17 -0500 ), one more file 5.txt
A: ( Wed, 01 Apr 2020 11:26:43 -0500 ), Screenshot mapping WMI entries to SLMGR DLV entries.png
A: ( Tue, 14 Jan 2020 13:10:59 -0500 ), slmgr into file.url
A: ( Thu, 04 Feb 2021 12:23:31 -0500 ), test1_20210123165009.txt
A: ( Thu, 04 Feb 2021 12:23:15 -0500 ), test2_20210124184449.txt
A: ( Wed, 27 Jan 2021 12:59:02 -0500 ), test3_20210125205107.txt
A: ( Wed, 27 Jan 2021 12:58:56 -0500 ), test4_20210126224733.txt
A: ( Wed, 01 Apr 2020 13:44:07 -0500 ), WMI style DLV answer v2.qna
A: ( Wed, 01 Apr 2020 13:44:29 -0500 ), WMI style DLV answer v3.qna
A: ( Wed, 01 Apr 2020 11:19:48 -0500 ), WMI style DLV answer.qna
T: 14.074 ms
I: plural ( time, string )
Code without the final collapse, to show the dates in order.
q: (((tuple string items ((integers in (it-1,maximum of (it-5;0))) of (number of tuple string items of it)) of it) of concatenation ", " of following texts of firsts ", " of (it as string) of unique values of (it as time) of tuple string items 1 of elements of it), ((tuple string items 0 of it, tuple string items 1 of it) of elements of it)) whose (item 0 of it = item 1 of item 1 of it) of set of (it as string) of (name of it, following text of first ", " of (it as string) of modification time of it) of files of folders ("/tmp";"c:\test")
A: 04 Feb 2021 12:23:31 -0500, ( test1_20210123165009.txt, 04 Feb 2021 12:23:31 -0500 )
A: 04 Feb 2021 12:23:15 -0500, ( test2_20210124184449.txt, 04 Feb 2021 12:23:15 -0500 )
A: 29 Jan 2021 17:55:23 -0500, ( Abc_20210115612456.txt, 29 Jan 2021 17:55:23 -0500 )
A: 29 Jan 2021 17:55:13 -0500, ( Abc_20210120342156.txt, 29 Jan 2021 17:55:13 -0500 )
A: 29 Jan 2021 17:55:04 -0500, ( Abc_20210126224733.txt, 29 Jan 2021 17:55:04 -0500 )
T: 11.200 ms
I: plural ( string, ( string, string ) )
Current full code for optimized newest 5 files in folder with reverse sort by modification date
q: items 0 of items 1 of (((tuple string items ((integers in (it-1,maximum of (it-5;0))) of (number of tuple string items of it)) of it) of concatenation ", " of following texts of firsts ", " of (it as string) of unique values of (it as time) of tuple string items 1 of elements of it), ((tuple string items 0 of it, tuple string items 1 of it) of elements of it)) whose (item 0 of it = item 1 of item 1 of it) of set of (it as string) of (name of it, following text of first ", " of (it as string) of modification time of it) of files of folders ("/tmp";"c:\test")
A: test1_20210123165009.txt
A: test2_20210124184449.txt
A: Abc_20210115612456.txt
A: Abc_20210120342156.txt
A: Abc_20210126224733.txt
T: 6.582 ms
I: plural string
And with indention and comments (hint - comments are bottom up to follow the logical flow)
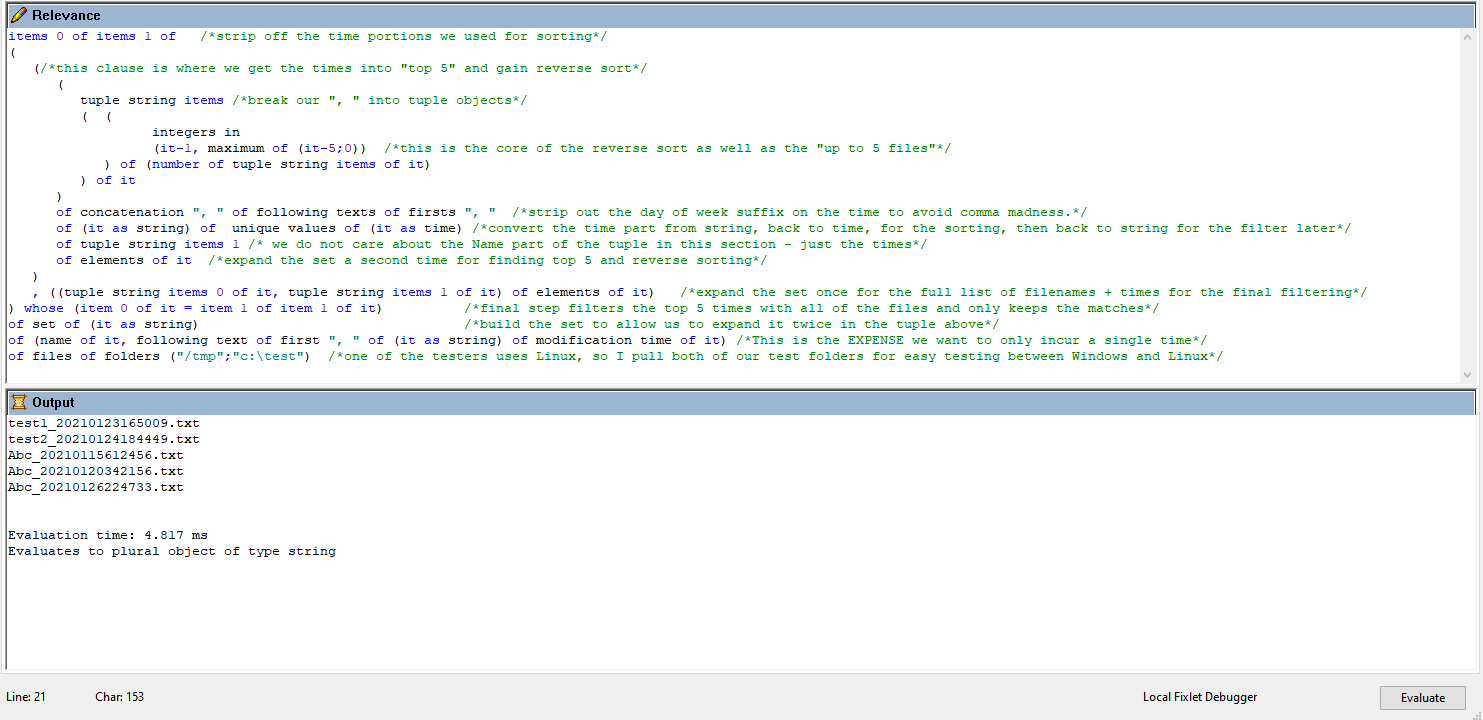
2 Likes
I don’t think that is needed for tuple string items in my testing. It seemed to handle less than 5 files just fine.