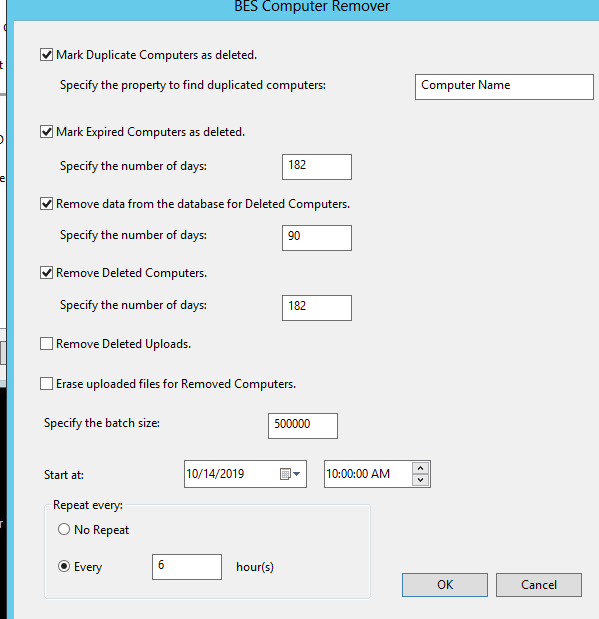
@ 2019-10-11 22:05:00.247 :
spid 61 is being blocked by spid 195 and inturn spid 195 is being blocked by spid 61 and 61 is chosen as deadlock
spid 61 query:
merge into LONGQUESTIONRESULTS as q using (values(@P1,@P2,@P3,@P4,@P5,@P6,@P7,@P8,@P9,@P10)) as v(siteid,analysisid, propertyid, computerid, isfailure, isplural, resultscount, resultstext, reportnumber, webuisiteid) on q.SiteID=v.siteid and q.AnalysisID=v.analysisid and q.PropertyID=v.propertyid and q.ComputerID=v.computerid when matched then update set IsFailure=v.isfailure, IsPlural=v.isplural, ResultsCount=v.resultscount, ResultsText=v.resultstext when not matched then insert(SiteID,AnalysisID,PropertyID,ComputerID,IsFailure,IsPlural,ResultsCount,ResultsText, WebuiSiteID) values(v.siteid,v.analysisid,v.propertyid, v.computerid,v.isfailure,v.isplural,v.resultscount,v.resultstext, v.webuisiteid);
spid 195 query:
DELETE TOP (@BatchSize) LONGQUESTIONRESULTS FROM LONGQUESTIONRESULTS L WHERE SiteID = L.SiteID AND AnalysisID = L.AnalysisID AND PropertyID = L.PropertyID AND ( NOT EXISTS ( select C.ComputerID FROM Computers C WHERE C.ComputerID = L.ComputerID ) OR EXISTS ( select C.ComputerID FROM Computers C WHERE C.IsDeleted = 1 AND C.ComputerID = L.ComputerID AND DateDiff(day, C.LastReportTime, GetUTCDate()) > @InactiveDays ) )