We have several files in the manual cache folder on the bigfix server. These files have crazy names including numbers and letters. Is there a way to open these files and see exactly what they do or what readable the contents are? is there a tool out there that can open these files or do I need to just add and extension to the file and if so, what extension. .txt doesn’t work.
By ‘manual cache folder’ on the BigFix Server, do you mean ..\BES Server\wwwrootbes\bfmirror\downloads\sha1? If so, what are you trying to do or achieve with the files within that folder?
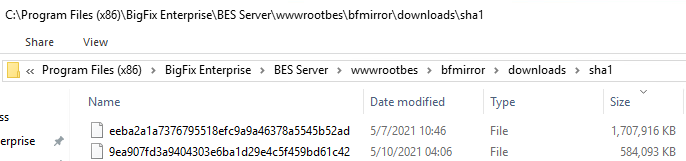
The files in the sha1 folder in question are part of the BigFix Server’s download cache, meaning, they are files that generally are being made available to Clients. The contents of this folder are typically managed automatically by the BigFix Server, however, as you note, you can manually cache files here too. The contents of the files will depend on what is being distributed to the Clients…things like Patches, updated applications, etc… The files in this folder would typically be referenced by Fixlets in your environment visible through the Console, Web Reports, or WebUI. For instance, if I look at the current largest file in my sha1 folder, I see the following:
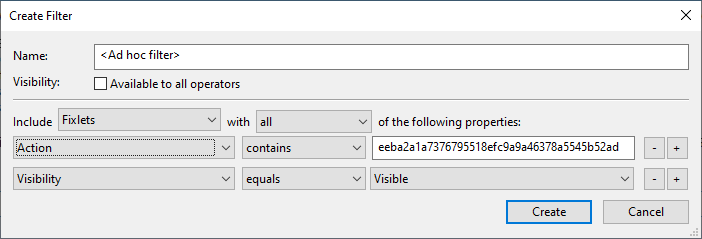
I can perform a search in the Console (one way is CTRL-F) for Fixlets whose actions contain this sha1 value to try to find the corresponding Fixlet (note: it could also have been in a Task, or possibly associated with content that has been deleted, so, this search is not guaranteed to find anything):
So, the file in question is really just the Windows MSU patch straight from Microsoft (windows10.0-kb5001347-x64_eeba2a1a7376795518efc9a9a46378a5545b52ad.msu) renamed to its SHA1 value. In this case, there’s nothing to ‘extract’…I could simply rename the file to <something.msu>, and it would be functional as a Microsoft update file.
Sounds like you are taking a software approach to a wetware problem. A conversation with HR would likely be more constructive than forensics on your server.
That said, there are approaches you could take. If this person is using the Manage Software Distribution library, you could use the same dashboard to export the packages and then use the 'BFArchive.exe" tool or the fixlet debugger to extract them.
Suppose you exported the file to “c:\temp\abc123.bfswd”.
In the Fixlet Debugger, open the Action tab, and enter the action script
extract c:\temp\abc123.bfswd
Hit the “Evaluate” button and the archive should get extracted into the same directory, c:\temp.
You have been given a lot of good information already, but I would just point out that “the weird names” are the “sha1” value of the file’s contents. Secure Hashing Algorithm 1 is an industry standard way of producing a “hash” value of some data such that it is “computationally unfeasible” that two different files of the same size will have the same hash value. Such algorithms have many uses in computer science, including validating the correctness of and integrity of file transfers. In this particular case, it has another benefit. The main reason for naming files this way when you use, for example, our Software Distribution system is to avoid name collisions.
To pick a simple example, suppose you have two completely different software packages that both come in a self-extracting archive named, for example, Setup.exe. You can’t put two different files both named “Setup.exe” in a single folder. But if you rename the file to its sha1 value, it is virtually impossible (though not TOTALLY impossible) that they will have the same name. This solves the problem of name collision without requiring a more wasteful solution like creating separate directories with, for example, the date/time the file was added. Then, how do you find it again? You’d need a database of names and directories.
But if you look at the fixlet you generate when you put a package in the Software Distribution system, the fixlet has the sha1 value so the fixlet “knows” that relationship. No extra data needed.
Here’s some documentation that can take you much further than you probably want to go:
First, on SHA1 itself:
Next, on the general concept of cryptographic hash functions:
Finally, on the general concept of hash functions (a vast topic in computer and information science):