I just ran into what appears to be a Bigfix character limitation for a single line in a text file. I’m hoping someone can confirm if that is indeed true.
The text file I have to parse has a line that contains 3654 characters. If I use QNA to view line 5 of the file, I get the first 1554 characters. Subsequent characters are considered line 6 by Bigfix. This obviously throws a wrench into parsing things at characters beyond 1554 as well as subsequent lines whose line numbers are now incremented. The same file displays correctly in Notepad ++ with all the information on the correct line numbers.
Yes there are indeed line length limits. Even better, the specific length varies by BES client version.
And there may also string length limits if you try to parse it without “lines of file”. Here’s something that might be able to parse it though if you don’t hit another limit.
This seems to work for me. I tried it with lines up to 11,567 in length: q: substrings separated by "%0d%0a" of concatenation of characters(bytes (integers in (0, size of it)) of file "c:\temp\longline.txt")
This is windows specific line ending. You could split based upon unix line endings and trim / ignore the extra line ending character if it exists.
I thought the limit was 2048 characters, at which point BigFix just pretends there is another line, even if there isn’t.
I’d probably recommend filing an RFE for this, I think this is a somewhat known issue.
This is a workaround to try to read the raw file data, but I think this runs into issues if the file contains non-ASCII characters or something like that. I forget where the issue is, but I think there is one.
Is there something specific you are trying to parse?
How big is the chunk of data you are trying to read?
Is the data all on 1 line?
In general, I don’t usually run into this limit as I am just pulling back specific little chunks of certain lines.
You should be able to start with the line where the data starts that you are interested in, then add the next few lines to it, then parse out what you are looking for there.
@JasonWalker The work-around you suggested does work.
My challenge now is that I have a dozens of custom tasks with many references to this particular file. As my developers have added a lot of new information to the file (appending to line length specifically), it is apparently going beyond Bigfix’s native limitations. While the data is correctly present, the line numbers used when parsing for particular information are no longer valid. So we either need to universally adopt Jason’s approach or where possible not use a specific line number but just ‘lines of file’ or get IBM to remove the artificial line length limitation.
@jgstew In a file that has multiple lines are variable length, knowing the specific line number becomes impossible should the length of those lines happen to exceed 1554 characters. (Example: So on machine A where the file has 1400 characters on line 4, I can parse that just fine by line number. Machines B, C, and D have line 4 sizes of 3000, 1750, and 2200 respectively. On those machines the same information parses on line 5 instead of line 4.)
If you have control over the file that is being generated, it would be much preferable if you can format it to use the “keys of file” and “variables of file” inspectors instead…
File content:
var1=value1
var2=value2
var3=value3
q: variables of file "c:\temp\longline.txt"
A: .var1=value1
A: .var2=value2
A: .var3=value3
T: 0.241 ms
I: plural string
q: following texts of firsts "=" of variables whose (preceding text of first "=" of it = ".var2") of file "c:\temp\longline.txt"
A: value2
T: 0.290 ms
I: plural substring
q: keys "var2" of file "c:\temp\longline.txt"
A: value2
T: 0.313 ms
I: plural string
I hadn’t considered that, but at least on my 9.5.4 debugger it seems to percent-encode for binary values. Here’s a cut at registry.pol (the use case that first came to mind for me):
q: concatenation of characters (bytes (integers in (0, size of it)) of file "c:\temp\registry.pol")
A: PReg%01%00%00%00[%00S%00o%00f%00t%00w%00a%00r%00e%00\%00A%00c%00t%00u%00a%00l%00 %00T%00o%00o%00l%00s%00\
Removing the line number when parsing and just using ‘lines of file’ seems to work most of the time as long as the description being parsed for is unique in the file. That’s the catch. If it isn’t unique, then I need to use the line number. Hopefully I’ll get an answer about that in the PMR.
Ironically, there is an active project underway to overhaul the system that produces this data. The intent is to have the new output as xml or json which will eliminate this issue.
Can you point out the PMR? As long as you stay in the relevance engine the limits are way higher but as soon as the information leaves the client there is definitely a limit in the length of the answer and lines will be broken there. Its in characters as of 9.5 (so the number of actual bytes per character doesn’t matter)
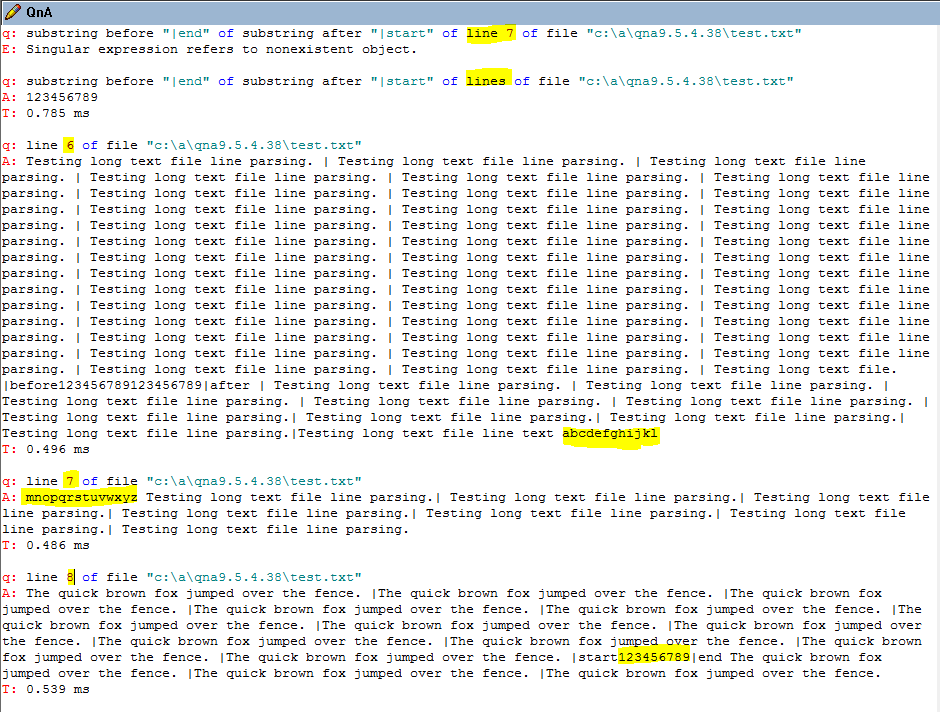
After a bit more testing, I have a better way to replicate the issue.
If there is text file with a line containing more that 2048 characters, then attempting to parse something from the line AFTER it will fail as characters 2049+ appear to wrap to the next line.
Here in this example, line 6 has more than 2048 characters. I’m trying to parse for a string in actual line 7 (which has less than 2048 characters). If I specify the line number, it fails as characters 2049+ spill over into the following line. Line 8 in QNA is actually line 7 of the file.
Yes this would be expected. There is a character limit on an answer so yes the long line will be broken up into the maximum length possible to return. This is reflected in the line number as well it seems though that seems a bit confusing when internally it should be able to handle the line at any length. Let me look internally how we do this particular count.
The PMR response: “Right now, the line is being truncated after exceeding 2048 characters and not before,
that is actually by design and not considered a bug.” It sure feels like a bug … I feel like this limitation isn’t well known or documented.
I opened an RFE on this topic. Please cast your vote: Line Limits RFE
Jumping into this old thread with a similar, but less complicated request.
I’ve got a TXT file and I want to read the first characters of the file before the first space in line 1 of the file. Typically the information I need is the first 5 characters, so I started with this:
if (exists file “C:\text.txt”) then (first 5 of line 1 of file “C:\text.txt”) else “N/A”
However, some endpoints contain the information in just 3 characters, which resulted in unwanted spaces and additional characters in the output.
I tried this:
if (exists file “C:\text.txt”) then (first substring separated by “%20” of line 1 of file “C:\text.txt”) else “N/A”
But that resulted in an error message.
If I write it this way I get all the information from line 1 of my TXT file:
if (exists file “C:\text.txt”) then (substrings separated by “%20” of line 1 of file “C:\text.txt”) else “N/A”
but I really only want that first substring of characters before the first space on line 1 of the file.