I’ve had multiple relays with over 10K clients reporting in (about 10,700 at it’s peak). To start with, I had major concerns around implementing this so I conducted tests to verify the relay could handle the capacity. I also made setting changes to ease the load on the relay. The only functionality I was fulfilling was general IEM maintenance, collecting initial software scan data and then collecting capacity data every 30 mins. So in essence I was delivering and receiving quite a bit of data. Clients were set up with Manual Relay selection with primary, secondary and a Fail-over Relay.
The relays in question were dedicated top level relays (approx 4 cores, 8GB RAM on RedHat VM’s).
To try and minimize the impact on the relay I changed:
_BESClient_Report_MinimumInterval from 15 to 60 seconds
Changed Client Heartbeats from 15 mins to 30 mins
Ensured I had no Analysis running more often than 30 mins/every report
And I also increased the time for retries for clients during relay selection when they get a refused connection.
The observed behaviors of the relays was actually very normal. I did not experience relays under any particular load - to be honest it wasn’t even touching the sides in terms of CPU and RAM. Disk I/O and Network traffic were the most observable aspects although it still wasn’t causing excess load.
However, what you need to avoid:
If your sending out an action to all the clients that are reporting into the relay, stagger it over time. As you said,the actual limitation is the number of simultaneous connections, you want to avoid having clients trying to report back at the same time. If you stagger actions, then the clients will gradually report back in an orderly fashion and you won’t reach the max connections limit. This way a Relay can easily service a large number of clients.
Otherwise what you may observe is clients responding slightly slower when you deliver actions - due to the relay being busy servicing it’s maximum number, before moving on the the next bunch, or clients failing over to another relay.
A good place to check the load on the relay is by actively looking at your relay diagnostics page (http://RelayHost:52311/rd), paying particular attention to FillDB:
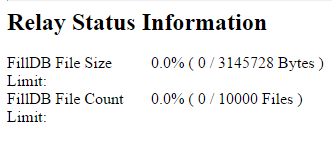
If this goes over 100%, the relay will be quite busy, however it should still eventually get through all the reports.
The only time I had an issue, was when a relay in a lower bandwidth area couldn’t process and pass on the Upload Manager Data fast enough as there was data coming in faster that the relay could pass it on the the IEM server. Basically the network connection was too slow so the data wasn’t going up fast enough. This meant that the Buffer Directory Max Count and Buffer Directory Max Size was getting bigger and bigger. However, even when both were 20x the default size, FillDB was still working ok and the relay was responsive enough to allow me to changed the settings for those clients (increase capacity scanning interval to 2 hours instead of 30 mins).
In terms of relating this to maintaining the performance, I would suggest that a relay could easily handle upwards of 2-3K clients without having to change the out of the box settings. Changing heartbeat, even to 20 mins, will help you though as it gives the relay more time to process the reports.
If you really want to push the limits and have faster performance, then you can look at adjusting the post results size and count.
_BESRelay_PostResults_ResultCountLimit
_BESRelay_PostResults_ResultTimeLimit
Decreasing both values will improve response time, but increase Network Traffic.
And of course increase the Max connections, however depends on what the limits are for the particular OS.