What platform are you hoping to do this on (Windows?) and is there anything else in the file before and after this? XML works based on path so we need to know all of the preceding and following content as well.
The following should work for grabbing the first one
(select "FLD_VALUE" of it as text) of selects "/CARSRV_STATUS/TERMINAL/FIELD[FLD_NAME = 'ESTOPONEXCEPTION']" of xml document of file "C:\pathto\test.xml"
Essentially we are using XML Pathing to find the node and then grabbing the value FLD_VALUE from it.
This gets us the XML Document:
xml document of file "C:\pathto\test.xml"
This gets us the field node with a FLD_NAME value of ESTOPONEXCEPTION
selects "/CARSRV_STATUS/TERMINAL/FIELD[FLD_NAME = 'ESTOPONEXCEPTION']" of xml document ...
Fantastic, but i get multi RESULT
Can you help me get the figure when a value other than 0
(select “FLD_VALUE” of it as text) of selects “/CARSRV_STATUS/TERMINAL/FIELD[FLD_NAME = ‘ESTOPONEXCEPTION’]” of xml document of file “C:\pathto\test.xml”
If you are getting multiple results then that means you’ve got multiple fields with a FLD_NAME of ESTOPONEXCEPTION so we need to figure out which one you actually want.
Can you let me know the XML parts that have a FIELD with a FLD_NAME of ESTOPONEXCEPTION?
And if you were looking at the file yourself how would you determine which is the value you want if there are two different values in the XML?
Are you saying that there may be multiple values but we want to ignore the ones that are 0? Can you elaborate on your last statement?
We’ve got two ways to do this – we can filter using xpath like we did with ESTOPONEXCEPTION or we can get our results and use relevance to filter it. I’ve given examples of both below:
Using XPATH
We can add another condition to our xpath like this:
(select "FLD_VALUE" of it as text) of selects "/CARSRV_STATUS/TERMINAL/FIELD[FLD_NAME = 'ESTOPONEXCEPTION' and FLD_VALUE!='0']" of xml document of file "C:\pathto\test.xml"
Notice the addition of FLD_VALUE!='0'
Note: As an exercise for the reader – this can also be simplified to just:
(it as text) of selects "/CARSRV_STATUS/TERMINAL/FIELD[FLD_NAME = 'ESTOPONEXCEPTION']/FLD_VALUE[. != '0']" of xml document of file "C:\pathto\test.xml"
Using Relevance
We can just add a whose (it) clause to our current relevance to filter using relevance:
it whose (it != "0") of (select "FLD_VALUE" of it as text) of selects "/CARSRV_STATUS/TERMINAL/FIELD[FLD_NAME = 'ESTOPONEXCEPTION']" of xml document of file "C:\pathto\test.xml"
WOW
it whose (it != “0”) of (select “FLD_VALUE” of it as text) of selects “/CARSRV_STATUS/TERMINAL/FIELD[FLD_NAME = ‘ESTOPONEXCEPTION’]” of xml document of file “C:\users\eastonb\desktop\test.xml”
I know this post is a bit old, but figured I’d try here since I am having a similar issue…
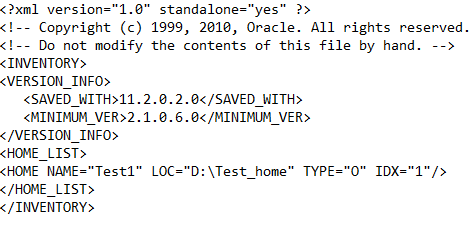
XML File:
<?xml version="1.0" standalone="yes" ?>
<!-- Copyright (c) 1999, 2010, Oracle. All rights reserved. -->
<!-- Do not modify the contents of this file by hand. -->
<INVENTORY>
<VERSION_INFO>
<SAVED_WITH>11.2.0.2.0</SAVED_WITH>
<MINIMUM_VER>2.1.0.6.0</MINIMUM_VER>
</VERSION_INFO>
<HOME_LIST>
<HOME NAME="Test1" LOC="D:\Test_home" TYPE="O" IDX="1"/>
</HOME_LIST>
</INVENTORY>
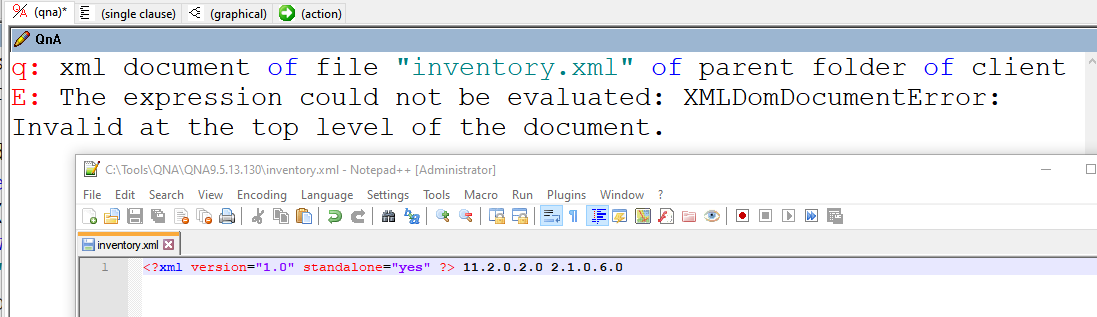
We are trying to simply pull the Home NAME as a result from the query below, but it returns as blank:
(it as text) of xpaths "INVENTORY/VERSION_INFO/HOME_LIST/HOME/Name" of xml document of file "C:\Program Files (x86)\Oracle\Inventory\ContentsXML\inventory.xml"
We do have success pulling the version from this same XML document via the command below:
If exists file "C:\Program Files (x86)\Oracle\Inventory\ContentsXML\inventory.xml" then ((node values of child nodes of selects "INVENTORY/VERSION_INFO/SAVED_WITH" of xml document of file "C:\Program Files (x86)\Oracle\Inventory\ContentsXML\inventory.xml") as trimmed string) else "Not Applicable"
I am sure we are overlooking something silly so if someone could assist it would be greatly appreciated!