That…is pretty neat. I haven’t considered this scenario but I have some thoughts.
The Downloads should not necessarily be related to the Gather state. From a Downloads perspective, the Root / Relay is just acting like any old web server that happens to be running on port 52311 instead of the usual port 443. What could happen though is that the downloads didn’t need to send a request upstream, if they were already cached in the bfmirror/downloads/sha1 at some level of Relay, and those cached downloads were removed with your gather reset.
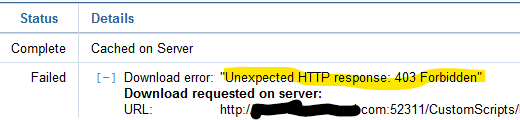
A 403 error is what we’d expect from a browser trying to download files from an Authenticating Relay. No client authentication certificate = Forbidden – and the client doesn’t try to send a certificate for a normal Download, just for gathering or sending download requests to a relay
Which leads me to ask, what kind of Direct Download settings do you have on the clients and/or their local Relays? Because the 403 makes me think they aren’t sending a “download request upstream”, it looks like something in the path is trying to do a direct download (like a curl download would behave).
See List of settings and detailed descriptions
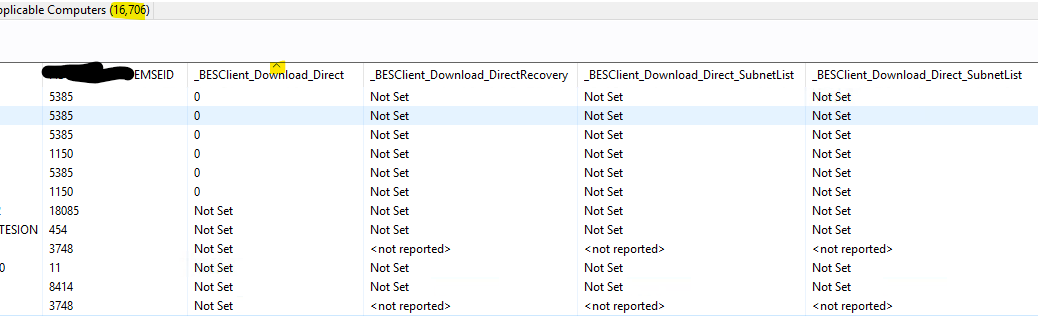
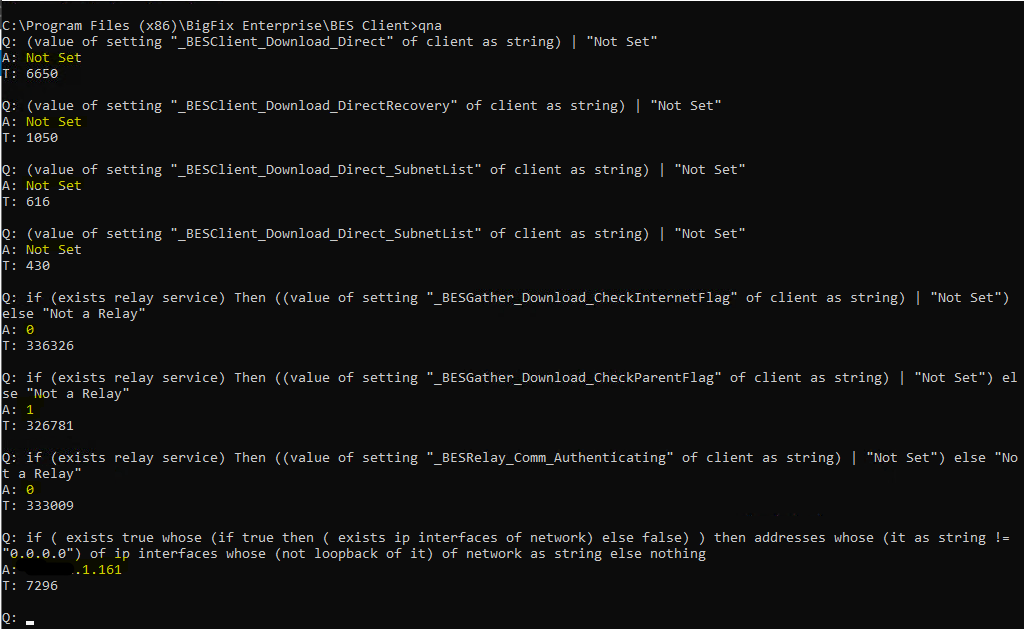
On clients I’d be looking for _BESClient_Download_Direct, _BESClient_Download_DirectRecovery, _BESClient_Download_Direct_SubnetList, and _BESClient_Download_Direct_SubnetList, as well as the topic on Managing Downloads at Managing Downloads
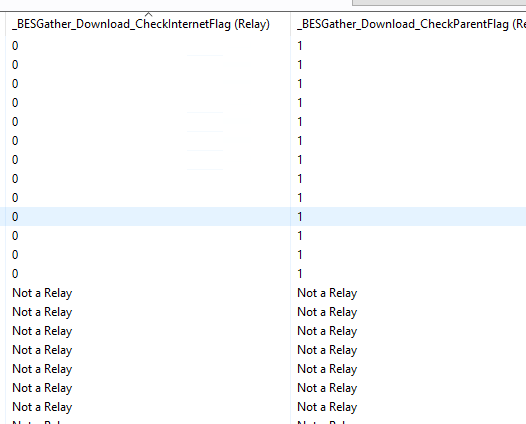
On Relays in the path between the client and the root, check the values for _BESGather_Download_CheckInternetFlag and _BESGather_Download_CheckParentFlag
What I’d want to ensure is that if any of the Download_Direct settings are applied on the clients, ensure that they also have _BESClient_Download_DirectRecovery configured so that if the Internet download fails, they’ll then try to send the request to an upstream relay (and honestly I haven’t tried this scenario so I can’t be positive that a 403 response correctly triggers the failaback recovery)
On the Relays, I’d also want to ensure that the ‘CheckParentFlag’ is set to 1 on every relay in the path. Otherwise the download request might not ever make it as far as the top-level relay (that resolves the real name of the root server).
This may have been broken for quite some time, and you might not have noticed it if the ‘CustomScripts’ files don’t change often and had already been cached on the lower-level relays. The setup you have now sounds like a traditional fake-root, what we would have done before the ‘Last Fallback Relay’ option was supported in the masthead. Now it might be simpler to use the ‘Last Fallback Relay’ masthead option instead, configuring some name that resolves to the local relay at each customer; that way there are no DNS games involved in faking the root server name, and all the Relays, Consoles, Web Reports, WebUI, etc. that need to reach the root directly, can, without HOSTS file entries.