We recently moved our server into a new data center, and I’m seeing the following messages in the BESRelay.log file … can anyone point me in the right direction?
Thu, 02 Apr 2015 11:28:49 -0400 - RelayNotifier10 (7316) - Error running task RelayNotifier10: HTTP Error 28: Timeout was reached: Connection timed out after 10000 milliseconds
Thu, 02 Apr 2015 11:28:49 -0400 - RelayNotifier7 (7304) - Error running task RelayNotifier7: HTTP Error 28: Timeout was reached: Connection timed out after 10015 milliseconds
Thu, 02 Apr 2015 11:30:38 -0400 - RelayNotifier3 (7288) - Error running task RelayNotifier3: HTTP Error 28: Timeout was reached: Connection timed out after 10000 milliseconds
You may need to increase the timeout beyond 10000 milliseconds. This might not be the cause of the error, but I would recommend increasing that a bit anyway and see if the errors become less frequent.
I think this is the correct parameter:
setting "_BESData_Comm_TimeoutSeconds"="20" on "{parameter "action issue date" of action}" for client
Hey JG or anyone else that may know, I also am getting these notifier issues on a few of my upper level relays, and the the times correspond when I have child relays not responding to actions. I have 9.2.2.21.
Would I use the _BESData_Comm_TimeoutSeconds setting on the top level relays only, or also on the child relays? Even though I increased this setting to 30 seconds on my top level relay, I still see the error saying 10 second timeout reached, etc., which leads me to believe that the error is coming from a child relay not responding in a timely manner??
I put in a ticket for this and I was asked to try out the HTTPRequestSender_Connect_TimeoutSeconds and I put a value of 45 to that, which I put on two upper level relays, but it appears to have made no difference. Waiting on a response back from them. Thank you
This means that the server is attempting to send TCP notifications to its top level relays as part of the the notifications process (to notify them of new content to gather), and the connection is not able to happen. This could be because the timeout is set too low as @jgstew mentioned. Or it could mean that something is blocking the TCP notification connection from happening (i.e. a firewall, a proxy, a bad network, a disconnected network, etc.)
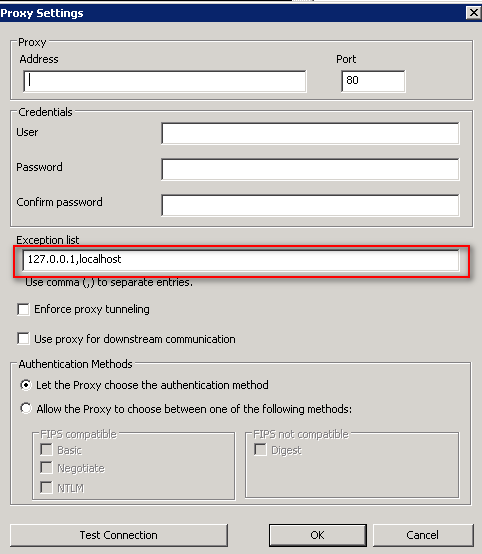
It could also be that you have a proxy setup between the BigFix server and the Internet and the BigFix server does not know the difference between your internal relay IP addresses and a public IP addresses so it attempts to go through the proxy to get to your top level internal relays, which of course is not going to happen.
If this is the case, what you will want to do is configure the exceptionlist for the proxy settings to have the IP addresses of all the relays that connect directly to the main BigFix server ( see the documentation ). IP addresses delimited by commas.
On Windows, you are given an interface to configure the proxy settings: BESAdmin.exe /setproxy
We don’t have any proxies in place. This error is fairly sporadic, but does occur a handful of times a night where it corresponds to a child relay timing out, and also it’s clients not getting an action and not responding. I am seeing these errors on the actual relay log on the top level relays, not from the bigfix sever itself. The majority of the jobs are running well, there are just times when we get these errors in the relaylogs.
Is the HTTPRequestSender_Connect_TimeoutSeconds setting the right way to go about this? If so, do I need to try this on the top level relays, or also on the child relays? Thank you in advance,
Please test. HTTPRequestSender_Connect_TimeoutSeconds should only need to be set higher on the top level relays as the error logged in the top level relay’s log is for a one way notification to its child relays.
Is there any sort of observable impact to the responsiveness (time to gather new content) of the deployment at the times these RelayNotifier messages appear in the top level relay logs?
If there is not a noticeable impact, and the condition happens at a time where responsiveness is not that important to your console operators (they give several hours for actions to complete, or there is not a tight maintenance window for the jobs to run in) then it may not be that necessary to increase the setting way from its default.
Some other things which may be causing this issue as per your description that the problem is sporadic.
The child relays may be overloaded. It is recommended that no more than 1000 endpoints be assigned to each relay to ensure enough connectivity at times of deployment busyness. You can check on the Deployment Health Checks dashboard for this information.
Check to see if the gathering of the actionsite on your relays is falling behind by a verision, or 2, or 7, etc. You can see this on the Deployment Health Checks dashboard under the Relay Health section. If the gather of the actionsite is lagging, then those RelayNotifier’s may indicate a slight impact.
Consider other things happening on your network at those times: Heavy load from taking actions, reduced bandwidth or QoS on network segments, etc.
I do not see documentation on my end for a setting named HTTPRequestSender_Connect_TimeoutSeconds; looking… I would not set it until I can confirm if it exists and what does.
Where are you seeing the timeout, on the parent relay or the child relay?
The _BESData_Comm_TimeoutSeconds needs to be increased on whichever one is giving the timeout notification, so that would be the children, not the parent.
Hey Jg and Ninja, the timeout is seen on both the child relay and the parent (top level) relay. A quick scenario, an action is taken on Server A in a store, it stays not reported for the duration of the action . After investigating, we notice that at the time the action was pushed, Server A client never gets the action. When I look at Server B, the local relay at the same store, we see the errors below. Each time I see these errors, it follows the same as below.
Tue, 24 May 2016 01:11:19 -0600 - 4804 - 35: GetURL failure on http://TopLevelRelay.domain.com:52311/bfmirror/bfsites/manydirlists_5/__fullsite_11ad8826e14a17d3f7ebbd699baa55efe618e894: HTTP Error 28: Timeout was reached: Connection timed out after 10015 milliseconds Tue, 24 May 2016 01:12:57 -0600 - ProcessMailboxQueue (1540) - Error running task ProcessMailboxQueue: HTTP Error 28: Timeout was reached: Connection timed out after 10000 milliseconds Tue, 24 May 2016 01:13:00 -0600 - PeriodicTasks (1544) - GetExpectedVersionOfParent Error: HTTP Error 28: Timeout was reached: Connection timed out after 10000 milliseconds Tue, 24 May 2016 01:13:10 -0600 - PeriodicTasks (1544) - Error running task UpdateAndSendRelayStatus: HTTP Error 28: Timeout
If I follow this to the Top Level relay I see the below errors at the same time.
Tue, 24 May 2016 01:013:23 -0700 - RelayNotifier8 (3444) - Error running task RelayNotifier8: HTTP Error 28: Timeout was reached: Connection timed out after 10000 milliseconds
Our top level relays have around 400 each child relays checking in. We are very balanced and our system runs pretty fast as well. The action sites are normally behind by maybe 1 at any given time, and that is a minority of the relays. Thanks for your help.
The log entries from the local (store level) relay indicate operations in which the client is attempting to gather. Gather from the mirror on the top level relay, and gather from the mailboxsite, etc. The gather operations are timing out.
Going the other way, the top level relay is having problems connecting to the local level relay to notify it of new updates to be gathered.
So both ways are problematic. You want to troubleshoot the network connection between top and local level relays to ensure they are efficient and of quality.
If you run a tracert between the two, are you able to determine if any part of the network path has high latency?
This only started occurring after I turned the cpu usage up my child relays to 20%, which seemed to work better at 10%, I had a lot of issues where my child relays were getting the actions, but not running them fast enough, but other clients within the same store would be working just fine. This led me to believe that the relays were evaluating more content; therefore, I sped up the CPU to 20%. I am throttling this down to 15% to see if I can find middle ground tonight. The bad thing about the failures at 20% is that it is causing all devices in that store to not get the action, compared to the errors at 10% where the majority were the child relay devices just not executing in enough time within my server automation window, and the other devices, in the same store with the child relay, were working fine. Please let me know if that makes sense. Thank you