Each property of an analysis has the “Evaluate Every:” option.
I am not sure of the best way to answer your question but I will say that it is important to NOT have more than one query for the same data more than once.
For example, I logged into a console that was handed down to me and saw they had a “Hard Drive Audit” analysis with properties on size and free space then they had a second analysis on “Hardware Information” with properties that pulled the same data. These are wasteful queries.
Although the “view” you see when you move, add, remove column headers in a computer group, analysis, site and so one are unique to you, it is much better to build those views with the data you need instead of creating an analysis to pull the data over again.
For example,
Create a analysis OR Custom Property to pull the Hard Drive Space and Free Space
Create another analysis (or set of custom properties) to pull CPU, Memory and other hardware information
Create a computer group and add those properties to the view so you can see then as you wish and not have to pull (query) the data again in a separate policy
Instead of a computer group, you can add the columns of one analysis to display in another analysis also.
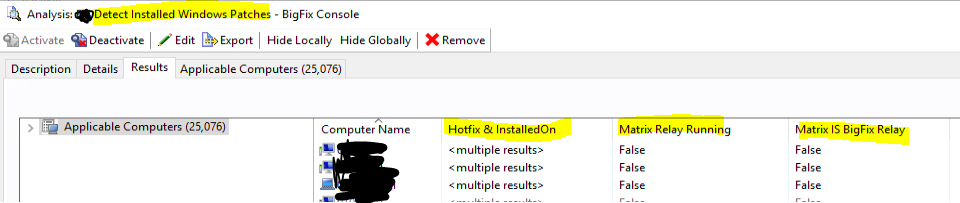
In the screenshot below, the analysis only has one property, the hotfix information. But I added the columns from a second analysis with information about the system and if it is a relay and if the relay service is running instead of creating a new property in this analysis to get me the same data. I have an analysis I call “Matrix” which contains a set of random properties that we use in the view of many other Analysis’s.
I wont say i am perfect at looking at the same thing twice, i do attempt to keep the queries unique and not double up on what is already around in another analysis.
I frequently will add columns when reviewing as well to put some of the data in context.
I tend to start of with frequent updates and then back off most updates to 6-12 hr intervals as most dont change often.
I have a very old history of object oriented programming (OOP). You should not write a program to pull data from somewhere in 10 different sections of the code. instead you write a subroutine to pull the data and then call the subroutine when you need that data. Reduces the lines of code and the need to update 10 sections of code instead of one when you have a bug or issue with that code.
By the way, it is very helpful to view BigFix as a OOP language. A computer is an object. There are built in properties such as the hostname, IP and AD path (Properties you can’t change in BigFix) and then there are custom properties that you can add such as a custom ID of your own. We are multi-tenant so we have a Entity ID assigned to each systems to “tie” it to the customer it belongs to. This Entity ID is unique for each customer and is a custom property for all machines. It helps me to view it this way because I think “big picture”, am I already pulling the data I need and if so, where, so I can just pull the property that already exists instead of pulling it again.