The procedure we usually use to verify if the WebUI is slowing down FillDB, is to correlate the WebUI ETL log with the FillDB performance log. If you do not have the FillDB performance log enabled, I would suggest enabling it and waiting for the issue to reoccur.
FillDB writes very frequently in the Performance log, unless it is stuck waiting for some lock to be released. So the procedure to troubleshoot the issue is:
as soon as you experience a report increase in the FillDB buffer directory, you can check the FillDB performance log and verify if FillDB is writing logs or if it really stuck
check the WebUI ETL log and verify if any data transfer is occurring between the WebUI and the server. You should see a line like:
bf:bfetl:debug GET
This means the WebUI has started requesting data and is processing them
wait for the WebUI to complete this ETL call. You should see in the log something like:
bf:bfetl:debug Updated <table_name> <rows_number> rows in seconds ( rows per second)
check again the FillDB performance log: if FillDB has restarted writing logs soon after the ETL completed, it means that the WebUI ETL had locked some data and prevented FillDB from updating them.
We have experienced in the past FillDB slowdowns related to the WebUI ETL and we are working to solve them with a future update.
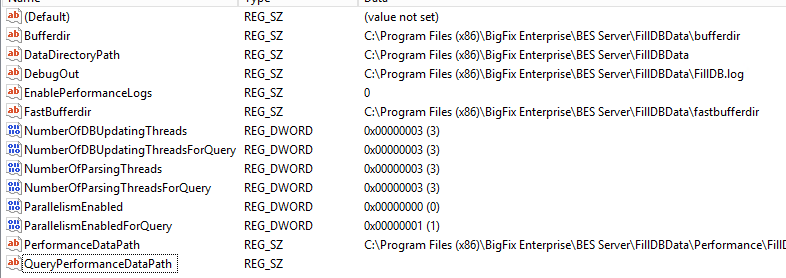
Apparently there is an issue with ParallelismEnabled particularly if the number of FillDB threads exceeds CPU cores available which could cause FillDB to stall.
I would try disabling it and look to enable it with more conservative thread counts once your issue is resolved.
How many CPU cores does your root server have? Does the root server have a local or remote database?
Well turning off ParallismEnabled didnt fix it… after about 6 hours of waiting for the Webui to initialize, the FillDbdata Bufferdir filled up with 722 files and stopped. all 8K machines in the master console greyed out … Stopping the Webui Service then flushed the BufferDir and everything burst back into life .
It is typically easy to see the impact of parallelism through the system monitoring. While disabling is good to rule things out, it has been very good at being self adapting.
In this case, I would suspect lock contention and a generally slow ETL process.
What does the Webui\ETL directory look like over time?
But I guess the parallelism settings are different given that they go into besserver.config on linux and not besclient.config which I find a bit unusual. It kind of makes sense, but client settings are generally a universal way to work with configuring bigfix across multiple OSes, so I tend to prefer them.
We see this today with 9.5.13. We kill and start the fillDB and/or BES Root service on the root server. About 15 minutes goes by after restarting and poof, the files process again.
We’ve had this issue through many versions and cannot pin it down. The short version is that FillDB will hang, you can only kill it and then restart it. What we have found is that it almost always happens a few days after a reboot of the BES. If after a restart of the BES, you later restart the FillDB on your own, it seems to run fine.
Check the space available on your DSA DR setup target. Our DR DB was bloated twice the size, had a case open for over a month to find out why, vendor never came back with an answer. We could not keep enough free space. Just kept adding and adding more disk. We stopped and disabled fillDB service on DR targets, then problem went away and a lot of other issues we were facing.
We will schedule a DR setup redo (drop DB) soon. Then we will watch the size again to see if there is a true defect. We then may just switch to another non-Bigfix replication solution, which there are a few.