Depending on your use case for the various external sites. It is possible you could subscribe only a handful of lab devices for example to the given external site to see which patches or whatever the content is would be needed for your environment. Then copy that content from the external site to a custom site when you are ready to use / deploy it.
In that way, any site update that occurs will only be sent to relays that have clients that are members of the site.
This would be difficult to manage though depending on your use case of course.
Also, another wild crazy idea for you. If you are only worried about the traffic generated by a specific site, its possible you could block just that single site from updating via a scheduled task. Either A with the host file modification that Jason mentioned, or even by placing a file within that sites folder on the relay and locking the file.
I’ve had an issue in my environment before where an outside process put a log file into a custom sites folder within the BigFix folder structure, this caused that single site to not be able to process updates, but all other sites remained working fine.
It’s similar to my previous UDP blocking via firewall idea, however this would only “block” a specific site.
If there are this few clients for each relay, then the batch delay won’t do much since the total time for all clients to be notified will still be very short.
As @JasonWalker mentioned already, if all of the traffic is going through relays like it should, then there should NOT be a network spike seen as the relays should cause the content to only get downloaded a single time over a particular link unless the relays have very small caches or if clients are talking to the wrong relays, or both. It could also be the case that you have remote relays talking directly to “top level relays” with slower links in between which could use a relay in those locations so that you have the traffic managed better for those network links. It feels like something like that, or clients talking to the wrong relays is what is happening here.
Yes, you are correct that the batch delay and count do not help this situation as my tests demonstrated.
For more background, we do have a highly structured relay affiliation structure in place where remote client prefer their local relay(s), then top-level, then fail-over. The clients and relays are respecting the affiliation process.
It is critical to delineate that the WAN traffic surges in issue had nothing to do with downloading packages, but only site metadata. I watched it all in real-time using WAN monitoring tools. There were no active deployments/downloads happening - only site changes. I have seen on multiple occasions where either internal or IBM publishing of sites creates the ‘WAN wave’.
The more we all discuss, there seems to be a configuration gap. We have the ‘stagger’ option to govern the download of content, but no apparent way to either ‘stagger’ or schedule the site metadata sync communication itself - particularly relay-to-relay within the hierarchy. The existing controls would generally work for few relays with large numbers of clients on each, but do not seem to help at all when there are many relays with few client each.
Thanks for the suggestions. I’ll weigh those options together with the advice that the engineer in my support case offers.
This doesn’t make sense if clients are all talking to their local relays as the site metadata will only be downloaded once per relay, so if there is at least 1 relay behind every WAN then the traffic should be extremely tiny and minimal.
We have seen issues where there are many slow links that have to be followed up the chain to the top level relays and there are links in the middle that are used for multiple relays below it and there being no relay at that point in the chain causes traffic congestion a bit in that location, which can be mitigated by putting a relay in the middle between the top level relays and the remote ones.
What you describe should only be possible if there isn’t a relay at the link that is being overwhelmed.
We’re have a “many relays, few clients” setup here too.
We have 40,000 clients spread across 7,000 remote sites, all managed from a central location. Each remote site has a BigFix relay installed. The WAN is a hub-and-spoke design, so the root server and top-level relays are all located in the “hub” .
Our method for avoiding “WAN waves” during gathers was to place all top-level relays behind a router that throttled all BigFix traffic. This worked great (for many years) until the Patches for Windows site was republished during the afternoon on 12/19.
A few minutes after our root server did that gather on the afternoon of 12/19, the networking team came screaming over about how BigFix had completely maxed out the WAN. This was confusing to us, as we were in a production freeze, so there were no running actions in BigFix that would have caused this … an afternoon gather of a site wasn’t even on our minds. Networking team ended up having the firewall block all BigFix WAN traffic so we could end the pain while still researching.
Turns out 1,500 remote site relays were directly connected to the root server… still unsure why, both their primary and secondary top-level relays were available the entire time. With the root server not being throttled and 1,500 remote relays connected to it, whatever communication happens between them during a site gather brought down the WAN ridiculously quickly.
So now we’re looking at implementing the “fake root” setup. Staggering and scheduling what happens between relays when gathers happen would be really nice to have in our environment.
It makes sense in that it’s still close to a “flat” architecture. Instead of a couple thousand clients reporting to a top level, it’s a couple thousand relays reporting to a top level, but same problem.
When something like a 200 MB site update happens (around the size of Patches for RHEL last I looked), with 2,000 relays, thats still 400 Gigabytes that has to go out on the wire from the top-level.
When we were faced with this on my network (where we were impacting SAN rather than WAN), we seriously considered rate-limiting the relays’ bandwidth.
I think we need Bigfix to do something in this area. To me the cleanest thing would be for site gathers to also respect the bandwidth limiting settings as action downloads.
This makes perfect sense to me as to what would cause this problem, definitely what I was speculating.
I can definitely see how that would be an issue if the BigFix infrastructure is too flat and their aren’t intermediate relays to prevent it from being downloaded many times over the same link.
It does seems like this would be a good idea, at least as far as something that could be optionally enabled and configured. I have a feeling doing so might slow things down all the time when enabled. I’ll have to look into it and see what is available now vs what would be useful to add.
IBM L3 responded to my case by acknowledging a configuration gap. While there are settings, as this thread previously discussed, to control relay-to-client notifications and metadata synchronization, there are not presently corresponding settings governing relay-to-relay notifications and metadata sync. Folks that are impacted seem to be those with many remote locations and relays. L3 official response was to submit an RFE.
If you would like to see the product incorporate settings governing relay-to-relay communications to schedule, throttle, and/or stagger parent to child relay notifications, please consider voting for this request for enhancement.
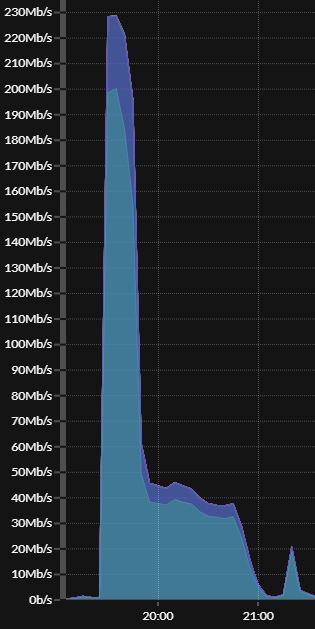
For a fresh example of what I’m talking about, this is a snapshot from Bigfix-specific notification communications across a WAN to 2200+ remote relays from last evening when IBM published several routine site updates. The goal is to reduce that spike to a gentle extended ripple.
Upvoted - but I still think it would be more effective for the team to implement a bandwidth throttle for gathers rather than a client time-of-day schedule, as a large number of relays/clients in the same timezone could still incur a penalty or require complex schedule staggering (i.e. my previous environment kept all systems in UTC timezone).
The issue with throttling gathers is that we want gathers to complete once they start very quickly. It would be too easy to get into an unknown state (think someone closing their laptop) if we don’t attempt to process a gather as quickly as possible, this includes the download and the application of the download.
That being said the client does the best it can to limit the download to the smallest size it can either through site diffs, full sites or individual files from the relays.